SQL Agrupa Datos Eficientemente con GROUP BY y Filtra Grupos con HAVING
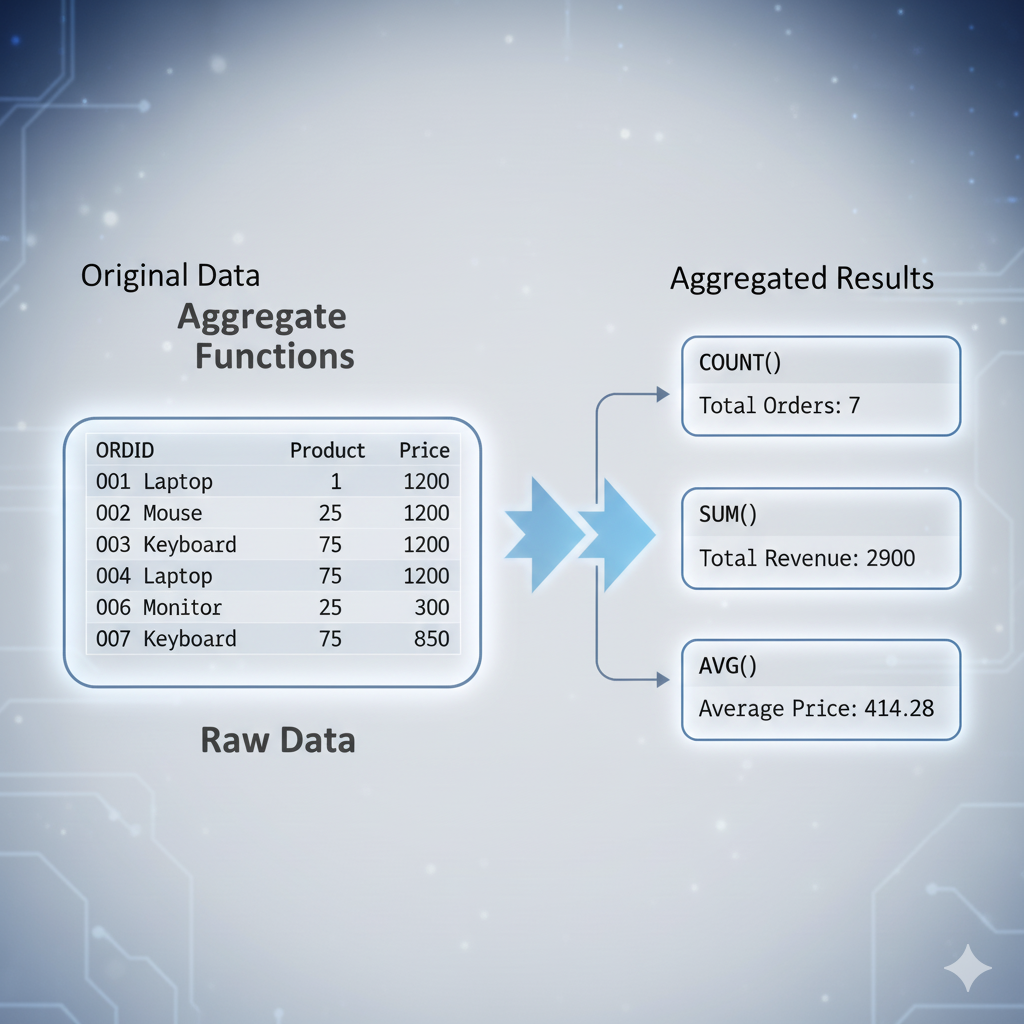
Hasta ahora, hemos visto cómo las funciones de agregación como COUNT, SUM y AVG nos permiten obtener un único valor de resumen de un conjunto completo de datos. Pero, ¿qué sucede si queremos esos resúmenes no para toda la tabla, sino para subconjuntos específicos, como el total de ventas por región, el número de empleados por departamento o el promedio de pedidos por cliente?
Para esto, SQL nos proporciona dos herramientas poderosas e interconectadas: la cláusula GROUP BY y la cláusula HAVING. Juntas, estas cláusulas te permiten organizar, resumir y filtrar datos a un nivel que va más allá de lo que la simple cláusula WHERE puede hacer.
La Cláusula GROUP BY: Segmentando Tus Datos
GROUP BY se utiliza para organizar filas que tienen los mismos valores en una o más columnas en un conjunto de filas de resumen. Para cada grupo, puedes aplicar funciones de agregación (como COUNT, SUM, AVG, MIN, MAX) para obtener un valor resumen para ese grupo.
Sintaxis Básica:
SELECT
columna_agrupacion,
funcion_agregacion(columna_numerica)
FROM
tabla
GROUP BY
columna_agrupacion;¿Cómo Funciona?
Imagina que tienes una tabla de Pedidos con columnas como id_pedido, id_cliente, fecha_pedido y monto. Si quieres saber el total de ventas por cliente, GROUP BY id_cliente agrupará todos los pedidos de un mismo cliente en un solo grupo, y luego SUM(monto) calculará el total para ese grupo.
Ejemplos Prácticos con GROUP BY:
- Total de Pedidos por Cliente:
SELECT id_cliente, COUNT(id_pedido) AS numero_pedidos FROM Pedidos GROUP BY id_cliente;Esto te dará una lista de cada
id_clientey el número total de pedidos que ha realizado. - Ventas Totales por Año:
SELECT YEAR(fecha_pedido) AS anio, SUM(monto) AS ventas_anuales FROM Pedidos GROUP BY YEAR(fecha_pedido);Utilizando una función de fecha, agrupamos los pedidos por el año en que se realizaron.
- Promedio Salarial por Departamento:
SELECT departamento, AVG(salario) AS salario_promedio FROM Empleados GROUP BY departamento;Obtendrás el salario promedio para cada departamento en tu tabla de empleados.
Regla Fundamental de GROUP BY:
Cuando utilizas GROUP BY, cualquier columna en tu cláusula SELECT que no sea parte de una función de agregación debe estar incluida en la cláusula GROUP BY. De lo contrario, SQL no sabría qué valor mostrar para esa columna dentro de un grupo.
Por ejemplo, si intentaras SELECT id_cliente, id_pedido, SUM(monto) FROM Pedidos GROUP BY id_cliente;, SQL no sabría qué id_pedido mostrar para un cliente que tiene múltiples pedidos.
La Cláusula HAVING: Filtrando Grupos Agregados
Una vez que has agrupado tus datos y calculado tus agregaciones, es posible que necesites filtrar esos grupos basándote en los valores agregados. Aquí es donde entra HAVING. La cláusula HAVING es a los grupos lo que WHERE es a las filas individuales.
No puedes usar funciones de agregación directamente en la cláusula WHERE porque WHERE se procesa *antes* de que se realicen las agregaciones. HAVING, en cambio, se procesa *después* de GROUP BY y las agregaciones, permitiéndote aplicar condiciones a los resultados de esas agregaciones.
Sintaxis Básica:
SELECT
columna_agrupacion,
funcion_agregacion(columna_numerica)
FROM
tabla
GROUP BY
columna_agrupacion
HAVING
condicion_agregacion;Ejemplos Prácticos con HAVING:
- Clientes con más de 5 Pedidos:
SELECT id_cliente, COUNT(id_pedido) AS numero_pedidos FROM Pedidos GROUP BY id_cliente HAVING COUNT(id_pedido) > 5;Esto solo mostrará los clientes que han realizado más de 5 pedidos en total.
- Departamentos con Salario Promedio Superior a 60000:
SELECT departamento, AVG(salario) AS salario_promedio FROM Empleados GROUP BY departamento HAVING AVG(salario) > 60000;Solo verás los departamentos donde el salario promedio de sus empleados supera los 60000.
- Productos con Ventas Totales Superiores a 10000 en el Último Año:
SELECT PR.nombre_producto, SUM(DP.cantidad * PR.precio_unitario) AS ventas_totales FROM Productos PR INNER JOIN DetallePedidos DP ON PR.id_producto = DP.id_producto INNER JOIN Pedidos P ON DP.id_pedido = P.id_pedido WHERE P.fecha_pedido >= DATE_SUB(CURDATE(), INTERVAL 1 YEAR) -- Filtrar por el último año ANTES de agrupar GROUP BY PR.nombre_producto HAVING SUM(DP.cantidad * PR.precio_unitario) > 10000;Aquí combinamos
WHEREpara filtrar las fechas de pedidos antes de agrupar, y luegoHAVINGpara filtrar los grupos de productos basados en el total de ventas.
La Diferencia Crucial entre WHERE y HAVING
Entender la secuencia de procesamiento es clave:
FROM/JOINs: Primero, las tablas se unen.WHERE: Las filas individuales se filtran *antes* de cualquier agrupación. Las funciones de agregación no se pueden usar aquí.GROUP BY: Las filas restantes se agrupan en base a las columnas especificadas.HAVING: Los grupos resultantes se filtran *después* de que se han aplicado las funciones de agregación. Aquí sí se pueden usar funciones de agregación.SELECT: Las columnas y expresiones (incluidas las funciones de agregación) se seleccionan para la salida final.ORDER BY: Los resultados finales se ordenan.
En resumen:
- Usa
WHEREpara filtrar filas individuales *antes* de agrupar. - Usa
HAVINGpara filtrar grupos *después* de agrupar y aplicar funciones de agregación.
Consideraciones Adicionales
- Múltiples Columnas en
GROUP BY: Puedes agrupar por varias columnas para crear subgrupos más específicos. Por ejemplo, `GROUP BY anio, mes` para ventas mensuales por año. NULLenGROUP BY: Los valoresNULLen las columnas de agrupación se tratan como un grupo separado.- Rendimiento: Las operaciones de agrupación pueden ser intensivas en recursos en grandes conjuntos de datos. Es eficiente filtrar la mayor cantidad posible de filas con
WHEREantes de que se realice la agrupación para reducir la cantidad de datos que el motor de la base de datos tiene que procesar.
Las cláusulas GROUP BY y HAVING son herramientas indispensable para el análisis de datos en SQL. Te permiten transformar un conjunto de datos brutos en resúmenes significativos y tomar decisiones informadas al identificar patrones, tendencias y excepciones dentro de tus datos.
Dominar la distinción y la aplicación correcta de WHERE y HAVING es un paso fundamental para escribir consultas SQL más potentes, claras y eficientes. ¡Empieza a agrupar y filtrar tus datos como un profesional!